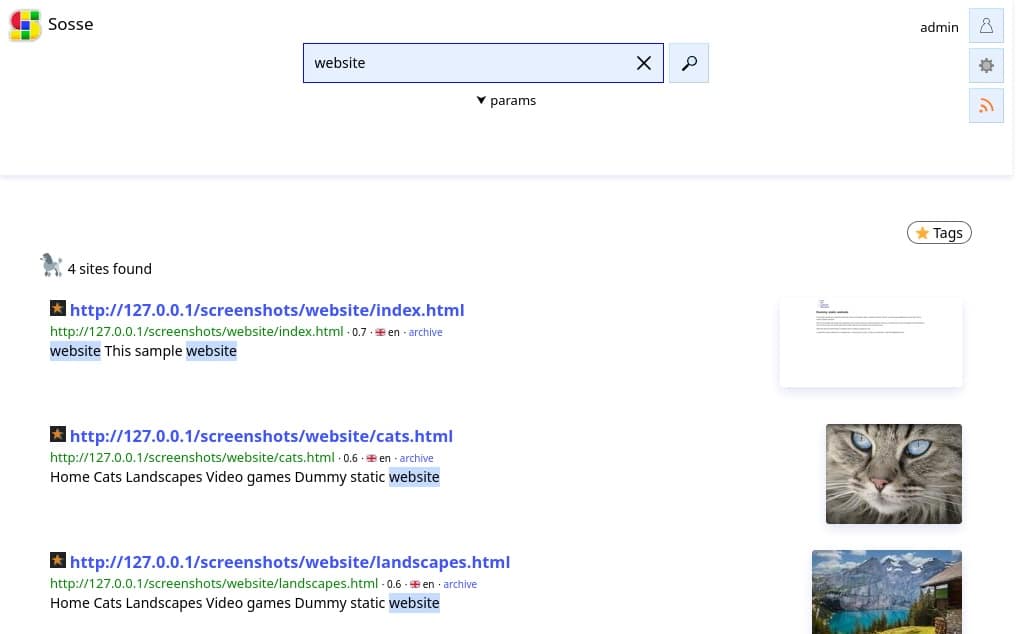
La llegada de Sosse, un motor de búsqueda y crawler de código abierto basado en Selenium, está marcando un nuevo estándar para desarrolladores, investigadores y entusiastas de los datos interesados en la exploración y archivado de la web moderna. Disponible en GitHub bajo licencia GNU AGPLv3, Sosse facilita la búsqueda avanzada, el archivado de páginas y la extracción de información incluso en sitios que dependen de JavaScript y contenido dinámico.
Funciones destacadas para un web crawling potente y flexible
Sosse ha sido diseñado para abarcar desde tareas simples de indexación hasta proyectos complejos de crawling y archivado. Entre sus principales características se encuentran:
- Búsqueda avanzada de páginas web: Permite buscar en el contenido de las páginas, incluidas aquellas renderizadas dinámicamente, mediante consultas complejas.
- Crawling recurrente: Automatiza la exploración de páginas en intervalos fijos o ajusta la frecuencia según detecte cambios en el contenido, optimizando así el uso de recursos.
- Archivado de páginas web: Ofrece la opción de guardar HTML, descargar recursos necesarios, ajustar enlaces para uso local y soportar la captura de contenido dinámico.
- Etiquetado y organización: Facilita la gestión y búsqueda de páginas mediante tags, mejorando la clasificación y el acceso a la información almacenada.
- Descarga masiva de archivos: Permite descargar archivos binarios en lote desde páginas web de interés.
- Integración vía webhooks: Se conecta fácilmente con servicios externos, plataformas de IA propietarias o autoalojadas, para extracción de datos avanzada, resumen automático, etiquetado, notificaciones y más.
- Feeds Atom generados automáticamente: Genera feeds para sitios web que no los tienen, avisando al usuario cuando aparece contenido relevante.
- Soporte de autenticación y permisos: El crawler puede acceder a páginas privadas, y los administradores gestionan permisos y estadísticas, mientras que los usuarios autenticados pueden realizar búsquedas privadas o incluso de forma anónima.
Tecnología y arquitectura
Sosse está desarrollado en Python, y utiliza Selenium junto con navegadores como Mozilla Firefox o Google Chromium para indexar páginas modernas dependientes de JavaScript. Para tareas de crawling más rápidas o menos complejas, también permite usar la biblioteca Requests. Todo el contenido y los metadatos se almacenan en PostgreSQL, asegurando escalabilidad y robustez.
Instalación y pruebas
La puesta en marcha es muy sencilla: basta con ejecutar la imagen Docker oficial con el comandodocker run -p 8005:80 biolds/sosse:stable
y acceder a través del navegador a http://127.0.0.1:8005/ con las credenciales por defecto (admin/admin). Para quienes prefieren una instalación más personalizada o persistencia avanzada de datos, la documentación detalla los diferentes métodos y opciones.
Una comunidad activa y en crecimiento
Sosse fomenta la participación abierta en GitHub y GitLab, donde los usuarios pueden enviar peticiones de nuevas funciones, reportar errores, contribuir al desarrollo y compartir ideas. Además, ofrece canales de soporte y debate a través de Discord, lo que facilita la colaboración y el aprendizaje compartido.
En resumen, Sosse se posiciona como una solución open source versátil y avanzada para crawling, archivado y búsqueda de contenido web, adaptándose tanto a necesidades de proyectos de investigación como a usos empresariales, gracias a su enfoque modular, integración con IA y facilidad de uso en entornos modernos y privados.