
Google acaba de presentar LangExtract, una librería de código abierto en Python diseñada para extraer información estructurada a partir de texto no estructurado, apoyándose en modelos de lenguaje como Gemini. La herramienta, que recuerda a Firecrawl en su planteamiento, se perfila como un recurso muy valioso para tareas de SEO, análisis de contenidos y auditoría de datos, al ofrecer resultados trazables, escalables y sin necesidad de complejos desarrollos adicionales.
Una necesidad en la era del contenido masivo
En un entorno donde las marcas, medios y empresas generan enormes volúmenes de información, identificar patrones, entidades y relaciones dentro de los textos es esencial para mejorar la visibilidad online. Hasta ahora, gran parte de este trabajo dependía de scrapers, regex personalizadas o procesos manuales que consumían tiempo y eran difíciles de mantener.
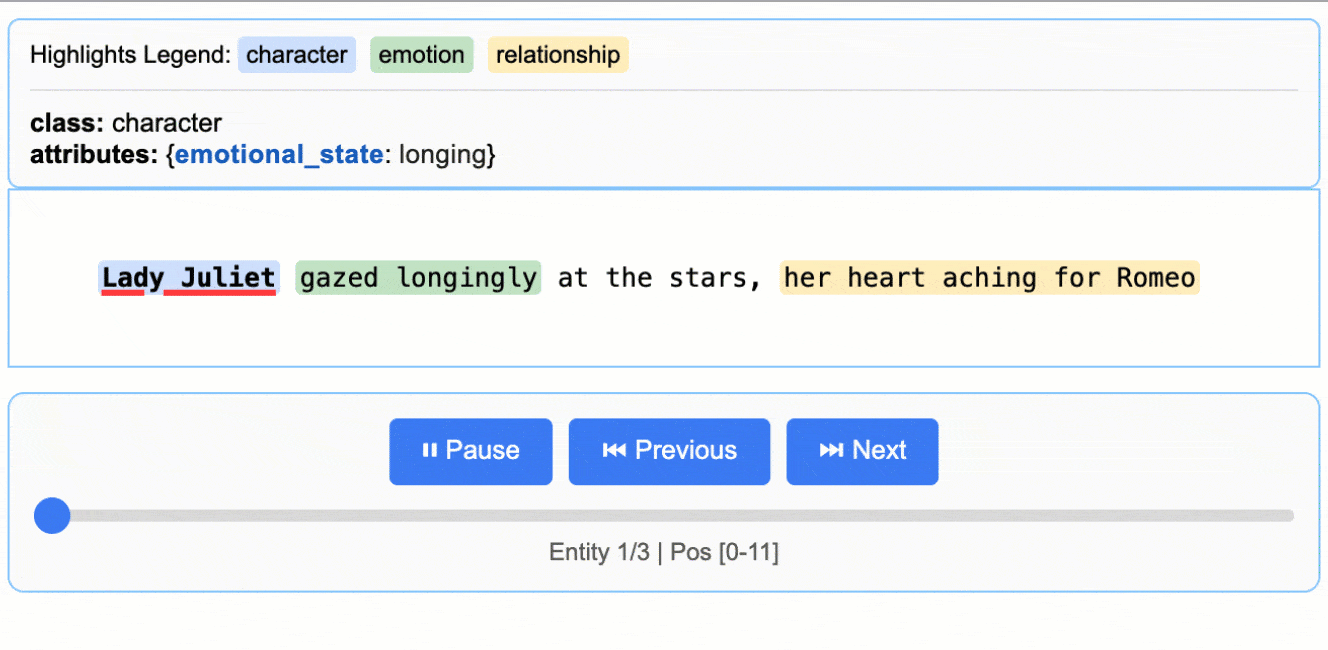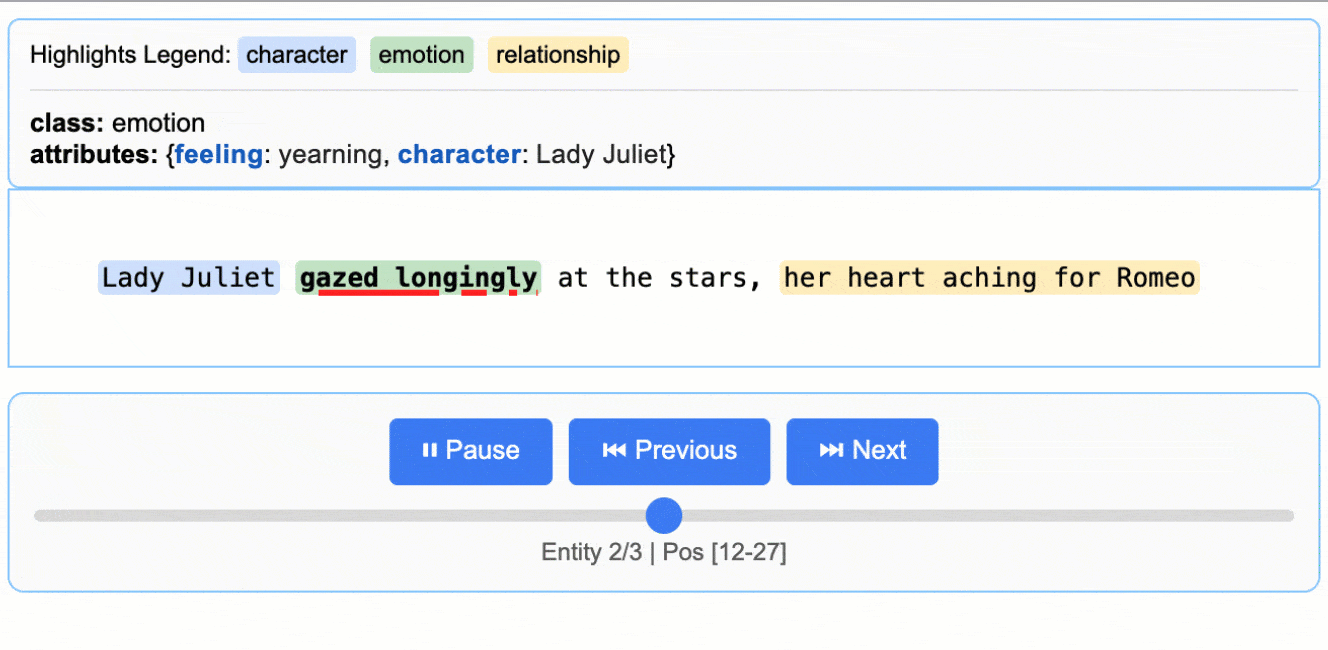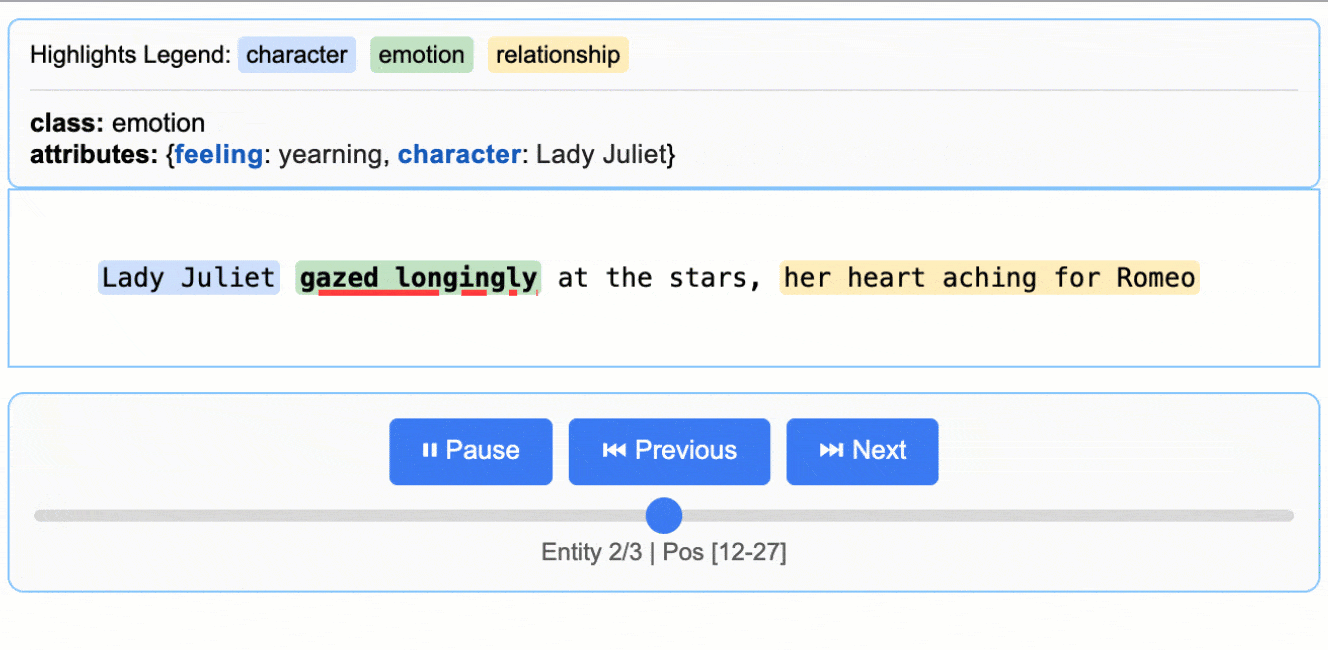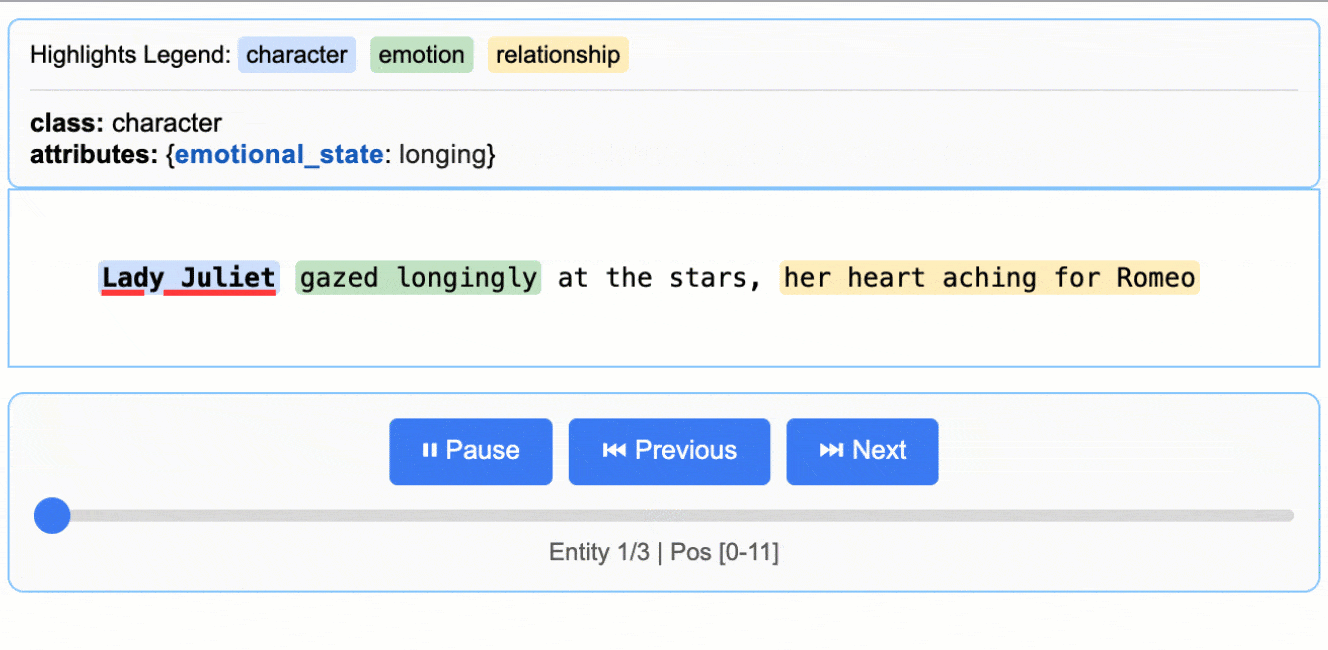
LangExtract promete simplificar esa complejidad: con solo definir un esquema de extracción y unos pocos ejemplos, los modelos pueden reconocer datos clave como fechas, entidades, emociones, categorías o relaciones semánticas. Todo ello con salidas consistentes en formatos estándar como JSON o CSV.
¿Por qué es especialmente útil para SEO?
La clave de LangExtract está en su combinación de trazabilidad, control y escalabilidad:
- Source grounding: cada dato extraído se vincula al fragmento exacto del texto, con offsets. Esto permite verificar dónde estaba originalmente y facilita auditorías por URL o frase, algo fundamental en estrategias SEO y de content marketing.
- Consistencia estructural: define un esquema y el modelo lo respeta, generando siempre salidas limpias y listas para ser procesadas en herramientas de análisis o reporting.
- Escalabilidad en documentos largos: mediante técnicas de chunking, paralelización y multipasadas, evita perder precisión en textos extensos, como blogs, catálogos o informes.
- Few-shot learning sin fine-tuning: basta con proporcionar ejemplos de calidad. LangExtract aprende el patrón deseado y lo aplica a nuevos contenidos, sin depender de entrenamientos costosos ni específicos de dominio.
Cómo funciona: láser sobre el contenido
Técnicamente, LangExtract opera como una capa de orquestación inteligente sobre LLMs, donde el usuario:
- Define el prompt de extracción (qué datos busca).
- Aporta ejemplos de referencia para guiar al modelo.
- Procesa el texto en uno o varios pasos, incluso directamente desde URLs.
- Recibe la salida estructurada con el respaldo de un visor interactivo en HTML para auditar y explorar los resultados.
Por ejemplo, un SEO podría pedir: “Extraer todos los productos, precios y opiniones de este texto de reseñas, vinculando cada precio con su producto exacto”. El sistema no solo devuelve la lista, sino que muestra dónde estaba cada fragmento dentro del documento.
Más allá del SEO: aplicaciones transversales
Aunque su lanzamiento ha llamado la atención en el mundo del marketing digital, LangExtract tiene un alcance mucho más amplio. Google lo ha probado en informes clínicos, radiología, literatura o textos legales, demostrando que puede adaptarse a cualquier dominio.
Esto abre la puerta a aplicaciones como:
- E-commerce: extracción de fichas de producto, variantes o valoraciones.
- Medios y blogs: categorización automática de artículos y detección de entidades.
- Investigación académica: análisis de papers para identificar referencias, métricas o conceptos clave.
- Legal y compliance: detección de cláusulas y términos relevantes en contratos.
El futuro: extracción estructurada como estándar
La irrupción de LangExtract confirma una tendencia clara: los modelos de lenguaje ya no solo generan texto, también lo organizan y verifican. Para el SEO, esto significa pasar de auditar manualmente decenas de URLs a contar con un sistema que extrae, organiza y presenta la información de forma verificable.
En un contexto donde Google impulsa AI Overviews y resultados cada vez más semánticos, disponer de herramientas que permitan entender y enriquecer el contenido con precisión será clave para mantener la relevancia y la competitividad online.
Preguntas frecuentes (FAQ)
1. ¿Qué diferencia a LangExtract de un scraper tradicional?
Un scraper extrae datos de la web siguiendo reglas rígidas (XPaths, regex). LangExtract, en cambio, utiliza modelos de lenguaje para interpretar el contenido y adaptarse a nuevos formatos con solo unos ejemplos, garantizando trazabilidad.
2. ¿LangExtract requiere usar Gemini obligatoriamente?
No. Aunque está optimizado para Gemini, también admite OpenAI (GPT) y modelos locales a través de Ollama, lo que lo hace flexible en entornos de desarrollo.
3. ¿Puede usarse en proyectos grandes?
Sí. Está pensado para documentos extensos y admite procesamiento paralelo y multipasadas, lo que le permite trabajar con catálogos, blogs o informes corporativos sin perder precisión.
4. ¿Es necesario entrenar un modelo propio?
No. LangExtract funciona en modo few-shot, lo que significa que basta con definir ejemplos de calidad para adaptarlo a cualquier dominio, sin entrenamientos adicionales.