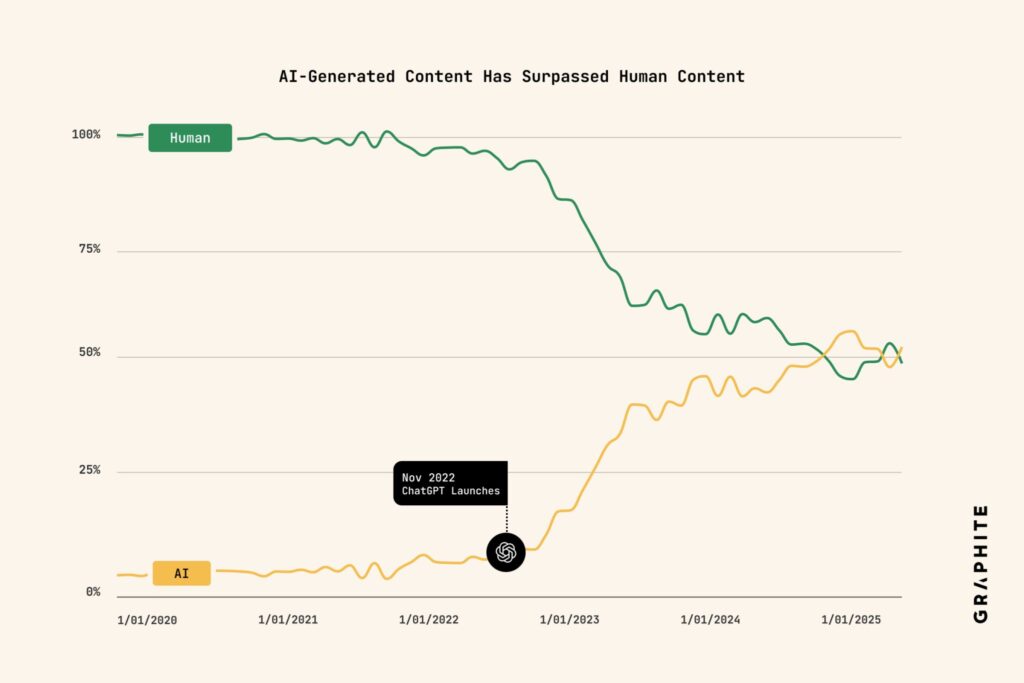
Puede que el “internet sintético” ya no sea una predicción, sino presente: un análisis publicado por Graphite sostiene que ya se publican más artículos generados por IA que por personas. La cifra llega con asteriscos —metodología, sesgos de muestreo, límites de los detectores—, pero el tendencia es difícil de ignorar: la producción automática de contenido escala más rápido que cualquier redacción humana.
Este es el resumen de lo que midieron, cómo lo midieron, qué limitaciones tiene el estudio y, sobre todo, qué cambia para medios, marcas, SEO, educación, publicidad y plataformas.
Qué midió el estudio y cómo
El conjunto. Los autores seleccionaron 65.000 URLs en inglés a partir de Common Crawl (una de las mayores colecciones públicas de la web). Filtraron páginas que:
- tuviesen marcado de artículo (schema),
- al menos 100 palabras,
- fecha de publicación entre enero de 2020 y mayo de 2025,
- y que su clasificador tipológico etiquetara como artículo o listicle.
El detector. Para decidir si un artículo era “IA” o “humano”, dividieron cada texto en bloques de 500 palabras y los pasaron por el detector de Surfer. Si más del 50 % del contenido se clasificaba como generado por IA, etiquetaban el artículo completo como “IA”.
Calibración de errores. Antes de clasificar los 65k textos, estimaron falsos positivos y falsos negativos:
- Falsos positivos (humanos que parecen IA). Asumieron que antes de ChatGPT (enero 2020–noviembre 2022) la gran mayoría de artículos eran humanos. En 15.894 piezas de ese periodo, el detector marcó 4,2 % como IA. Lo interpretan como una tasa aproximada de falsos positivos.
- Falsos negativos (IA que parece humana). Generaron 6.009 artículos con GPT-4o (temas variados) y el detector de Surfer identificó el 99,4 % como IA (esto implica un 0,6 % de falsos negativos en ese experimento).
Resultado. Con esa configuración, al clasificar los 65.000 artículos hallaron que la proporción de piezas etiquetadas como IA supera a las humanas. No publican las URLs concretas (para no señalar empresas), pero sí comparten las clasificaciones agregadas.
Lo que el estudio sí aporta
- Una señal potente de escala. Tomar 65k artículos de Common Crawl no es un censo, pero sí una foto amplia de la web anglófona con marcado de artículo. Que el “IA > humano” ya aparezca en una muestra así es, como mínimo, verosímil con lo que vemos a diario: catálogos, reseñas, guías “how-to”, afiliación, comparativas y sitios de nicho multiplicando su output.
- Un intento honesto de medir errores. El estudio no “cree a ciegas” en el detector: cuantifica falsos positivos y falsos negativos con dos conjuntos de referencia (pre-ChatGPT y GPT-4o sintético). No elimina todas las dudas, pero mejora la transparencia respecto a informes que solo dan el titular.
- Un punto de partida reproducible. La metodología (Common Crawl, bloques de 500 palabras, umbral >50 %) puede replicarse —o refutarse— por terceros con herramientas similares.
Dónde cojea (y por qué conviene leerlo con cuidado)
- El detector manda. Cambie el detector o su umbral y cambian los porcentajes. Surfer puede funcionar bien para GPT-4o “limpio”, pero ¿y para textos fuertemente editados por humanos, traducidos, resumidos o mezclas humano+IA? El 0,6 % de falsos negativos en GPT-4o no garantiza el mismo rendimiento sobre el “zoo” real de la web.
- Supuesto “pre-IA”. Asumir que antes de noviembre de 2022 todo era humano no es perfecto: ya existían modelos previos, “spinners” y plantillas. Ese 4,2 % de “IA” en la era pre-ChatGPT puede ser falso positivo… o una señal de automatización previa.
- Solo en inglés y con schema. La muestra se centra en artículos en inglés con marcado de artículo. Quedan fuera foros, redes sociales, páginas sin schema, otros idiomas y formatos (p. ej., PDFs o páginas corporativas sin marcado). No es “la web”, es un subconjunto.
- Sin URLs. Ocultar URLs evita “listas de la vergüenza”, pero restan verificabilidad. Sería deseable publicar muestras anónimas por tipo de sitio o sector para un escrutinio más fino.
- IA de hoy vs. IA de mañana. Los detectores pierden pie si los modelos cambian distribución, estilo o incorporan paráfrasis y edición humana. Lo que hoy es 99,4 % de acierto puede degradarse con tácticas de evasión.
Conclusión metodológica: el titular “ya hay más IA que humano” depende de un detector y una muestra concreta. Aun así, la tendencia (contenido automatizado creciendo más rápido que el humano) encaja con señales del mercado: explosión de “content ops”, caída de costes por palabra, catálogos infinitos y “agentes” generando resúmenes, reseñas y FAQs a escala.
Qué significa para cada actor
1) Para medios y creadores
- Diferenciarse deja de ser opcional. El “commodity content” (qué es, cómo, top-10) es el primero en comoditizarse. La ventaja competitiva pasa por reporting original, datos propios, acceso, criterio y estilo.
- Transparencia como activo. Etiquetar procesos (humano, IA asistida, IA) no solo es ético: construye confianza y reduce riesgos reputacionales cuando surgen errores.
2) Para marcas y SEO
- Estrategia de datos propios (first-party). Los buscadores y asistentes darán más peso a señales de autoridad verificable: estudios internos, datos de uso, benchmarks propios, documentación técnica, comunidad.
- E-E-A-T en serio. Experiencia, expertise, autoridad y confianza se prueban con pruebas (citas, fuentes, metodología), no con “palabras clave”.
- Menos “volumen”, más “valor”. La carrera por “publicar más que nadie” acelera la canibalización y el ruido. Guías vivas y actualizadas superan a 10 clones caducados.
3) Para plataformas y buscadores
- Provenance > detección. Los detectores son útiles pero frágiles. La industria avanza hacia señales de procedencia (p. ej., C2PA) y firmas a nivel de origen. Menos “adivinar”, más verificar.
- Re-ranking por utilidad. Respuestas de IA y listados deberán priorizar utilidad, actualidad, diversidad y origen frente a textos SEO-friendly sin sustancia.
4) Para educación y administraciones
- Políticas realistas. Detectar IA no es infalible y penaliza a veces a autores legítimos (sesgo de idioma/estilo). Mejor combinar revisión formativa, encargos prácticos, viva-voz y proyectos con trazabilidad.
- Alfabetización algorítmica. Enseñar a leer críticamente en la era de lo sintético vale tanto como enseñar a escribir.
5) Para publicidad y marcas (brand safety)
- Inventario sintético ≠ mala calidad por defecto, pero exige verificación. La planificación deberá incluir listas de inclusión, métricas de engagement auténtico y controles de fraude afinados a la IA.
Tres escenarios que ya se asoman
- La “web de los resúmenes”. Capas de IA que resumen otras capas de IA. Sin intervención humana, se corre el riesgo de deriva y ecos de errores.
- El péndulo de la utilidad. Frente a la inflación de texto, ganan quienes aportan herramientas, datos interactivos, comparadores, calculadoras y experiencias.
- El sello de origen. La presión regulatoria y de mercado empujará marcado de procedencia (C2PA, firmas), especialmente en noticias, salud, finanzas y educación.
Qué hacer hoy (lista accionable)
- Medios:
- Invierta en reporting y verificación.
- Establezca un estilo y una voz inconfundibles.
- Documente flujos human-in-the-loop cuando use IA y etiquete.
- Marcas/SEO:
- Construya páginas pilar con datos propios, casos reales y recursos descargables.
- Revise inventarios IA y despublique lo redundante/caduco.
- Añada esquemas ricos (eventos, productos, autoría), pero no confíe solo en schema: aporte evidencia.
- Educación:
- Rediseñe evaluaciones con defensas orales, versionado y proyectos.
- Explique límites de los detectores y riesgos de falsos positivos.
- Anunciantes:
- Exijan transparencia de inventario y métricas contra fraude adaptadas a IA.
- Prioricen contenidos con procedencia y señales de calidad.
Conclusión
El estudio de Graphite no es perfecto, pero pone números a algo que todos intuyen: la web está llenándose de texto generado por máquinas más rápido de lo que las redacciones pueden escribir. La respuesta no es nostalgismo, sino elevar el listón: criterio, evidencia, procedencia y utilidad. En un mar de palabras, lo escaso vuelve a ser lo valioso.
Preguntas frecuentes
¿Cómo detectar si un artículo está escrito por IA (y qué límites tiene hacerlo)?
Los detectores analizan patrones estadísticos y funcionan mejor con textos “puros” de IA y peor con ediciones humanas, traducciones o paráfrasis. Úselos como señal, no como veredicto. Combínelos con procedencia (p. ej., C2PA), metadatos, trazabilidad editorial y revisión humana.
¿Cómo afecta la “web sintética” al SEO de mi empresa?
Los listados se saturan de “más de lo mismo”. Para posicionar, aporte contenido verificable, datos propios, experiencia y utilidad (herramientas, demos, comparadores). El volumen por el volumen ya no es ventaja: Google y los asistentes priorizan calidad y autoridad.
¿Es arriesgado publicar contenido generado por IA sin revisión?
Sí. Riesgo de errores factuales, alucinaciones, copyright, reputación y publicidad engañosa. Si usa IA, implante revisión editorial, políticas de atribución y, cuando aplique, etiquetado. En sectores regulados (salud, finanzas), extremar la validación.
¿Qué pueden hacer los medios para diferenciarse en un entorno dominado por IA?
Invertir en periodismo original, datos exclusivos, investigación, criterio y estilo propio; construir comunidad; y ser transparentes sobre el uso de IA. La credibilidad es un activo: cuídela con procesos, no con promesas.
vía: graphite.io